Serving a Transformer model converting Text to SQL with Huggingface and MLflow
As machine learning continues to mature, here is an intro on how to use a T5 model to generate SQL queries from text questions and serve it…

As machine learning continues to mature, here is an intro on how to use a T5 model to generate SQL queries from text questions and serve it via a REST API.
Machine Learning for code completion got a lot of press with the release of OpenAI Codex which powers GitHub Copilot. Many companies are tackling this problem and making progress is now quicker thanks to the better tooling and techniques.
In the 10 years of evolution of the Hue SQL Editor, investing and switching to a parser based autocomplete was one of the top three best decisions. The parsers have even being reused by most of the competitiors. This was done five years ago and now new (complementary) approaches are worth investigating.
Here are three SQL topics that could be simplified via ML:
Text to SQL →a text question get converted into an SQL query
SQL to Text →getting help on understanding what a SQL query is doing
Table Question Answering → literally ask questions on a grid dataset
Let’s have an intro with the generation of an SQL query from a text question.
For this we pick an existing model named dbernsohn/t5_wikisql_SQL2en.
Most of the difficult work has already been done by building the model and fine tuning it on the WikiSQL dataset.

Let’s run the model with a simple question:
> python text2sql.py predict --query="How many people live in the USA?""SELECT COUNT Live FROM table WHERE Country = united states AND Name: text"Bonus: this quick CLI based on a previous tutorial allows to interact easily with the model
Obviously the results are not pixel perfect and a lot more can be done but this is a good start. Now let’s see how serving the model as an API works:
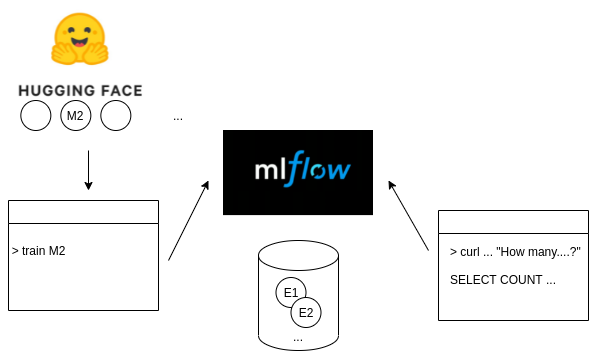

For this we will use MLflow which provides a lot of the glue to automate the tedious engineering management of ML models.
The API is simply local here but MLflow can automate the pushes and deploys of the models in production environments. In our case we just want to register it:
python text2sql.py trainAnd after starting the mlflow ui we can see the experiment:

Now we select the iteration we want to serve:
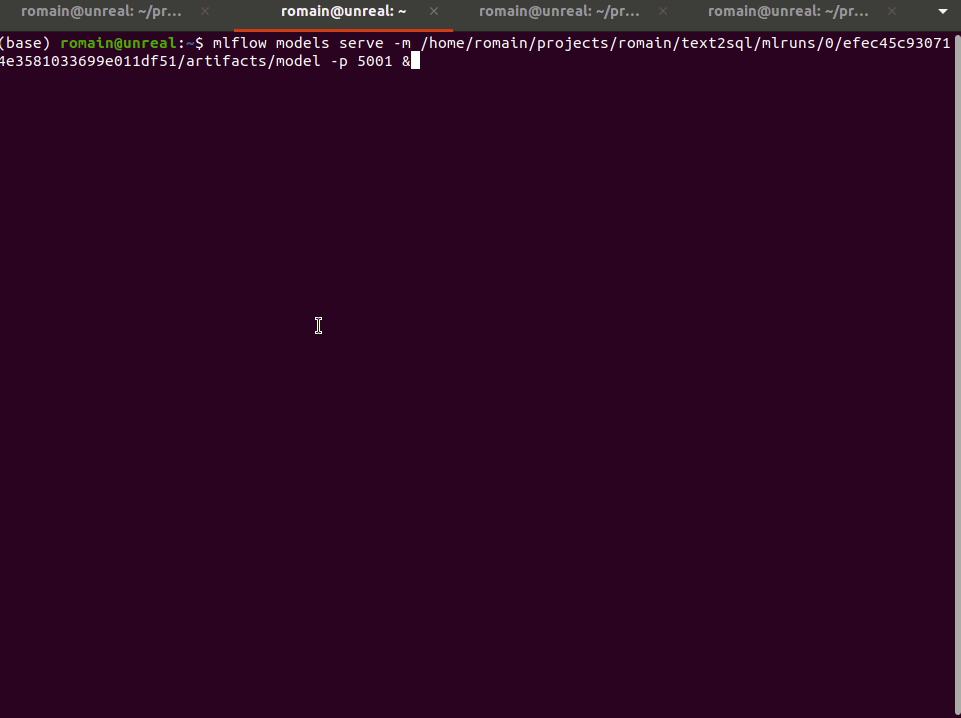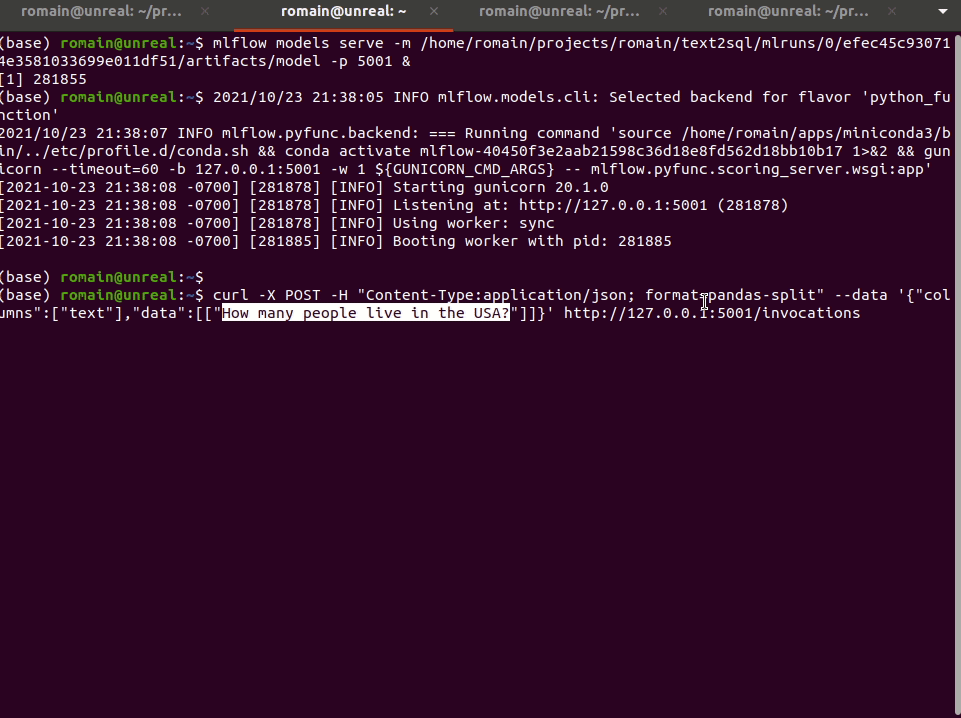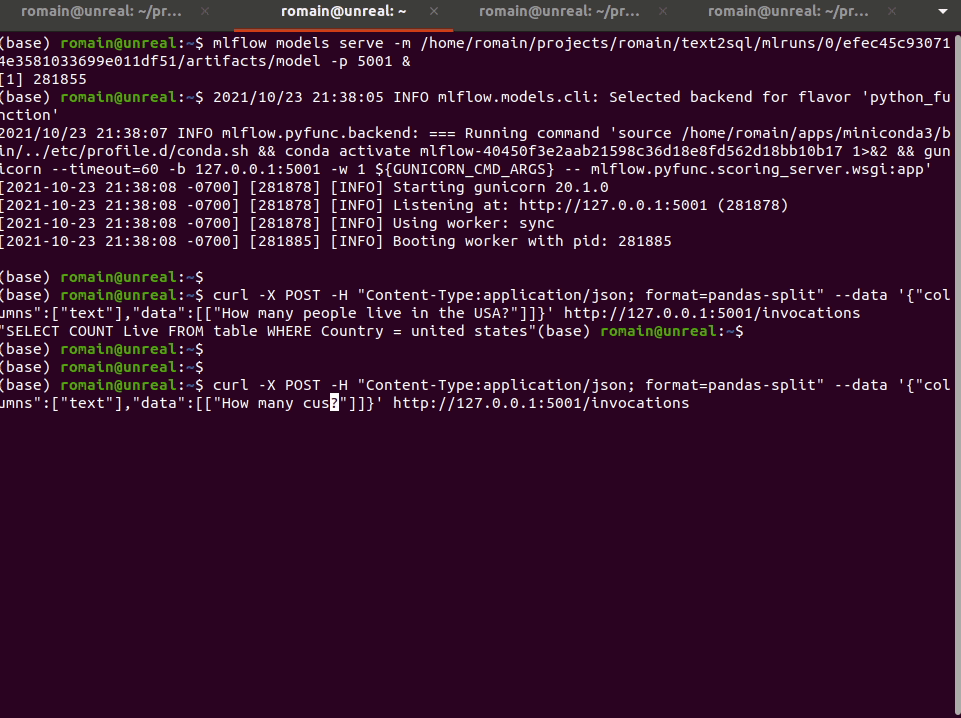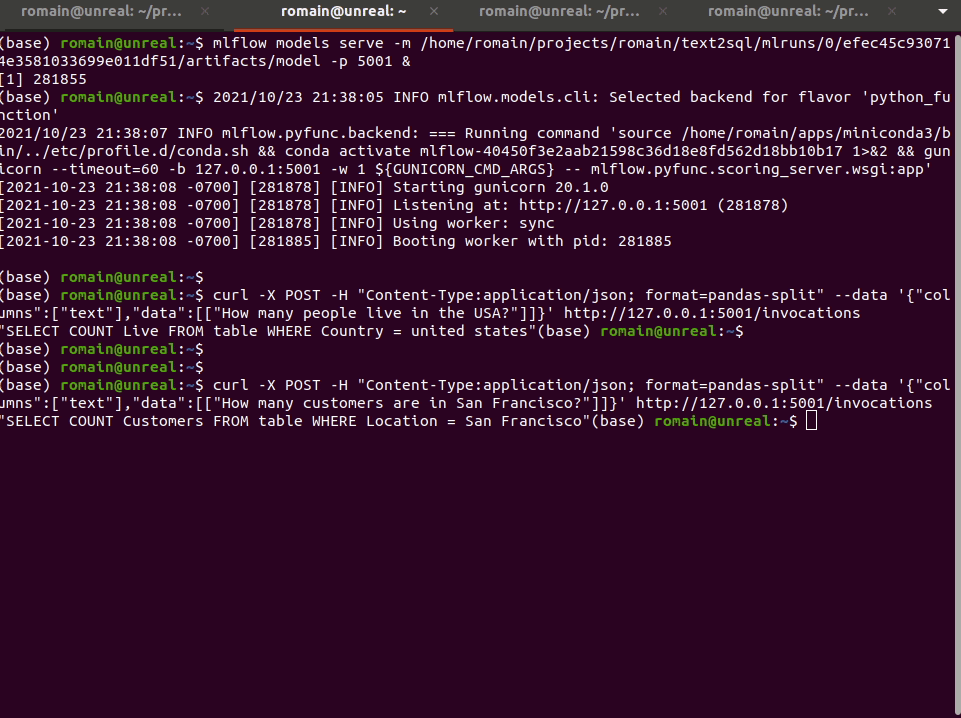
mlflow models serve -m /home/romain/projects/romain/text2sql/mlruns/0/efec45c930714e3581033699e011df51/artifacts/model -p 5001And then can directly query it!
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["text"],"data":[["How many people live in the USA?"]]}' http://127.0.0.1:5001/invocations"SELECT COUNT Live FROM table WHERE Country = united states AND Name: text"And that’s it!
The project is in a Github repo. As a follow-up you can also find a detailed exampled how to to manage a Bayesian Model with MLflow.
In the next episodes we will see how to integrate the ML API into your own SQL Editor and improve the model!